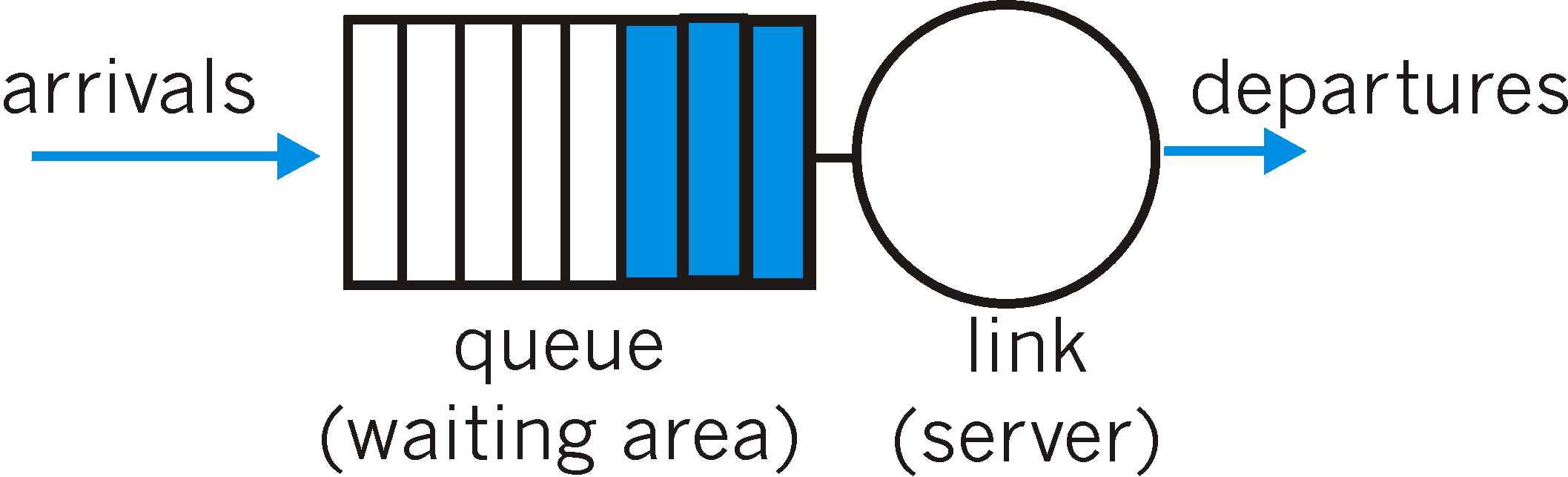
Figure 6.6-1: FIFO queuing abstraction
In the previous section we identified the important underlying principles in providing quality of service (QoS) guarantees to networked multimedia applications. In this section, we will examine various mechanisms that are used to provides these QoS guarantees. In the following section, we will then examine how these mechanisms can be combined to provide various forms of Quality of Service in the Internet.
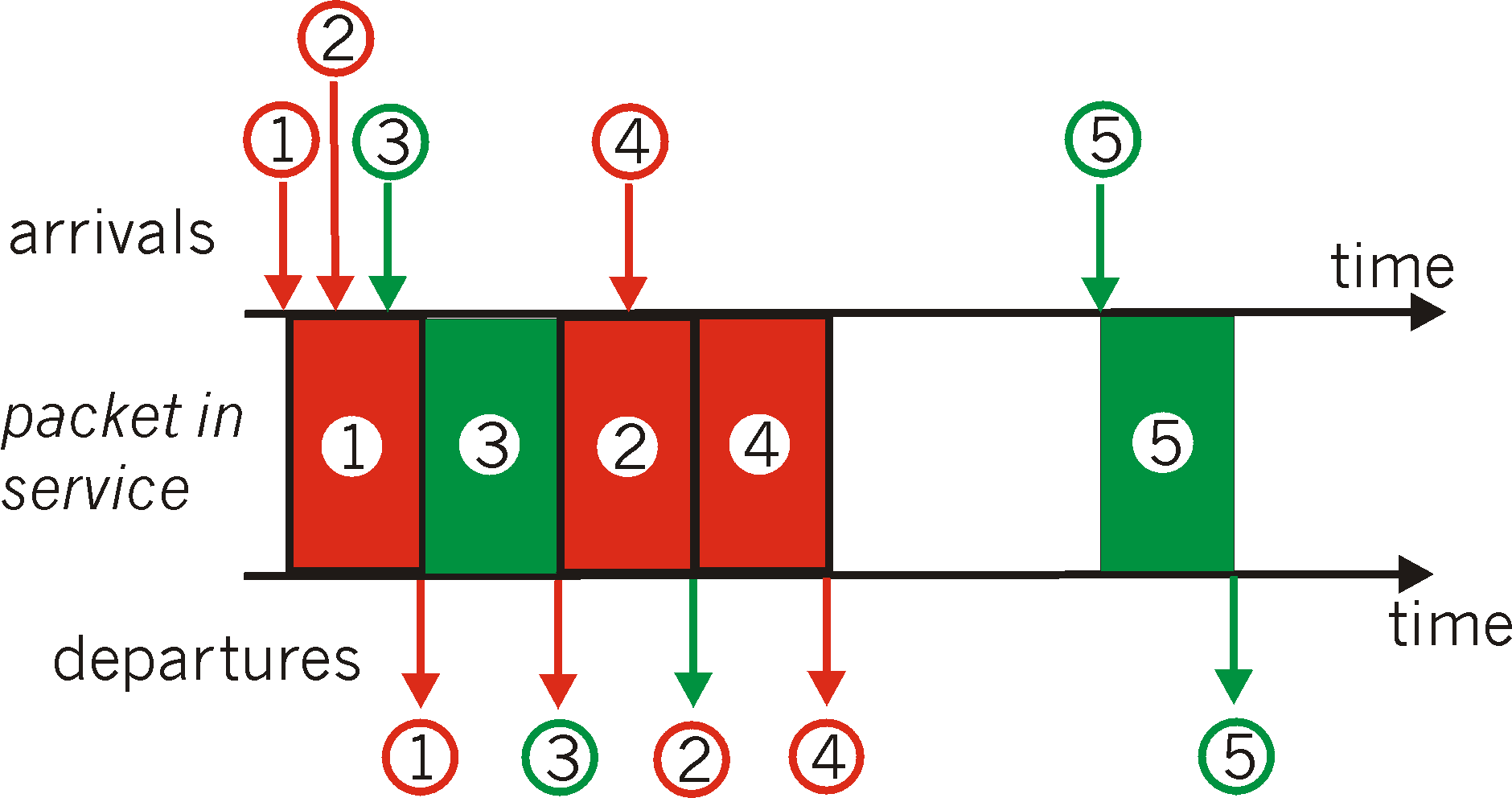
The FIFO scheduling discipline (also known as First-Come-First-Served - FCFS) selects packets for link transmission in the same order in which they arrived at the output link queue. We're all familiar with FIFO queuing from bus stops (particularly in England, where queuing seems to have been perfected) or other service centers, where arriving customers join the back of the single waiting line, remain in order, and are then served when they reach the front of the line.
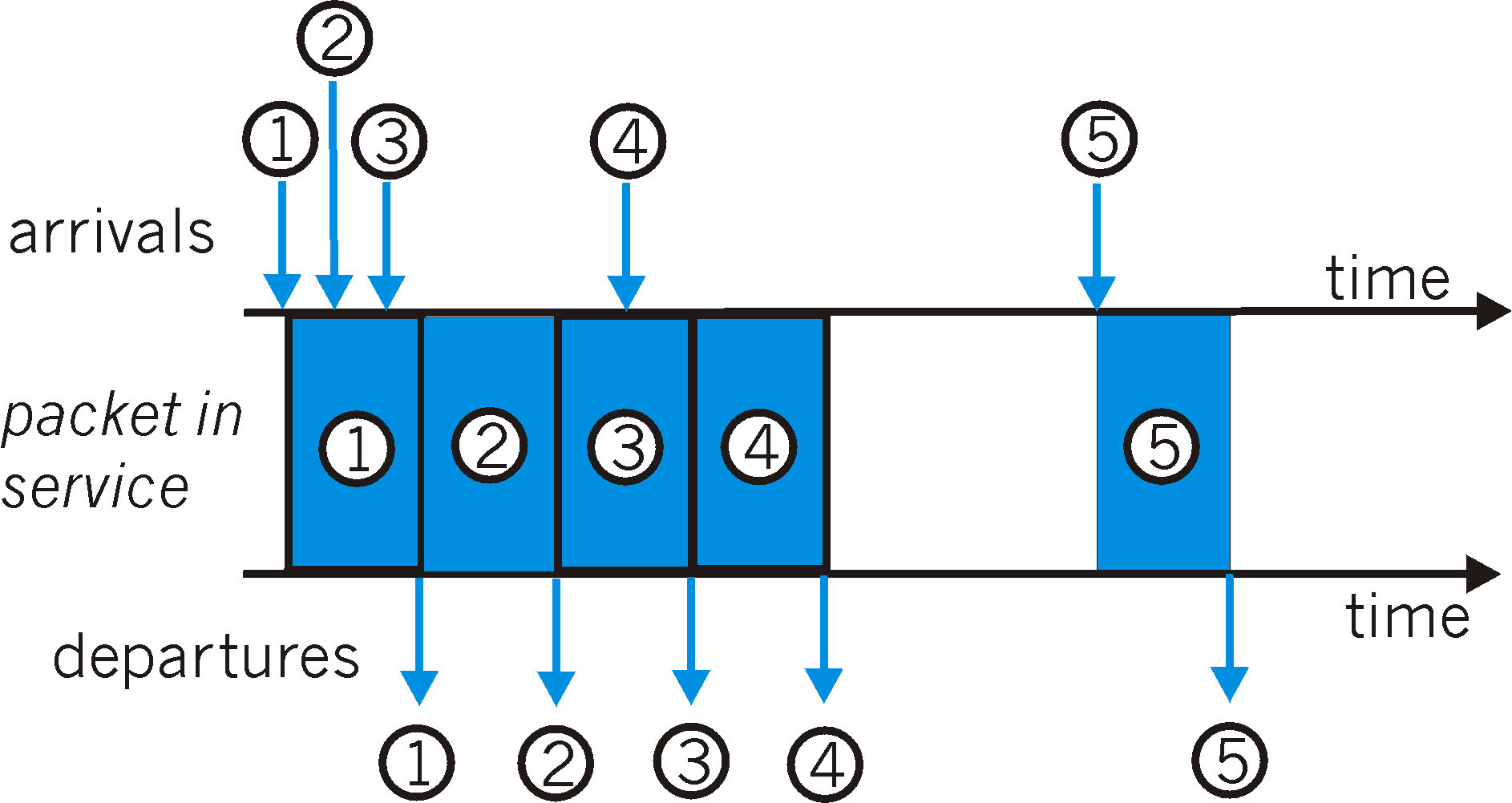
Figure 6.6-2 shows an example of the FIFO queue in operation. Packet arrivals are indicated by numbered arrows above the upper timeline, with the number indicating the order in which the packet arrived. Individual packet departures are shown below the lower timeline. The time that a packet spends in service (being transmitted) is indicated by the shaded rectangle between the two timelines. Because of the FIFO discipline, packets leave in the same order in which they arrived. Note that after the departure of packet 4, the link remains idle (since packets 1 through 4 have been transmitted and removed from the queue) until the arrival of packet 5.
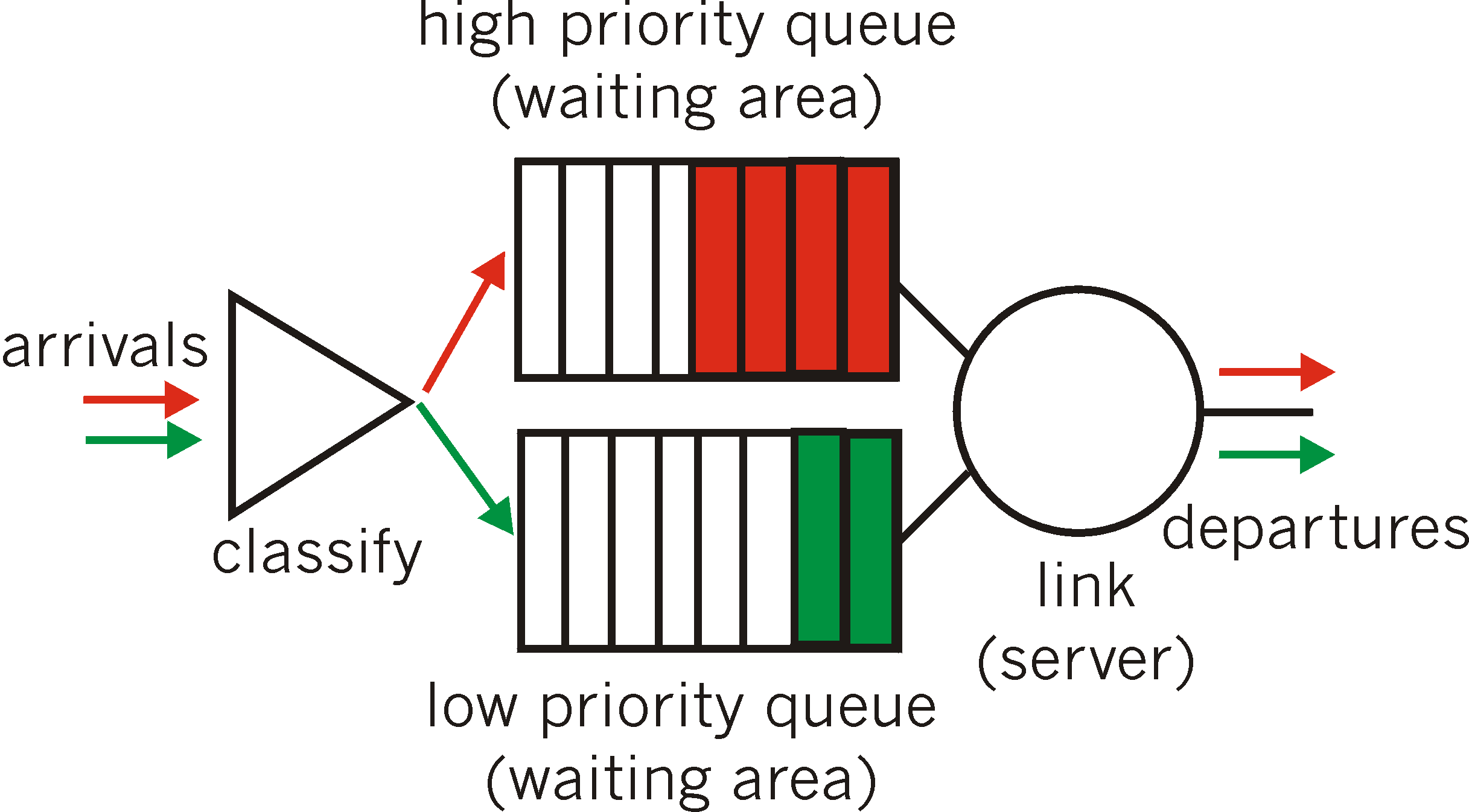
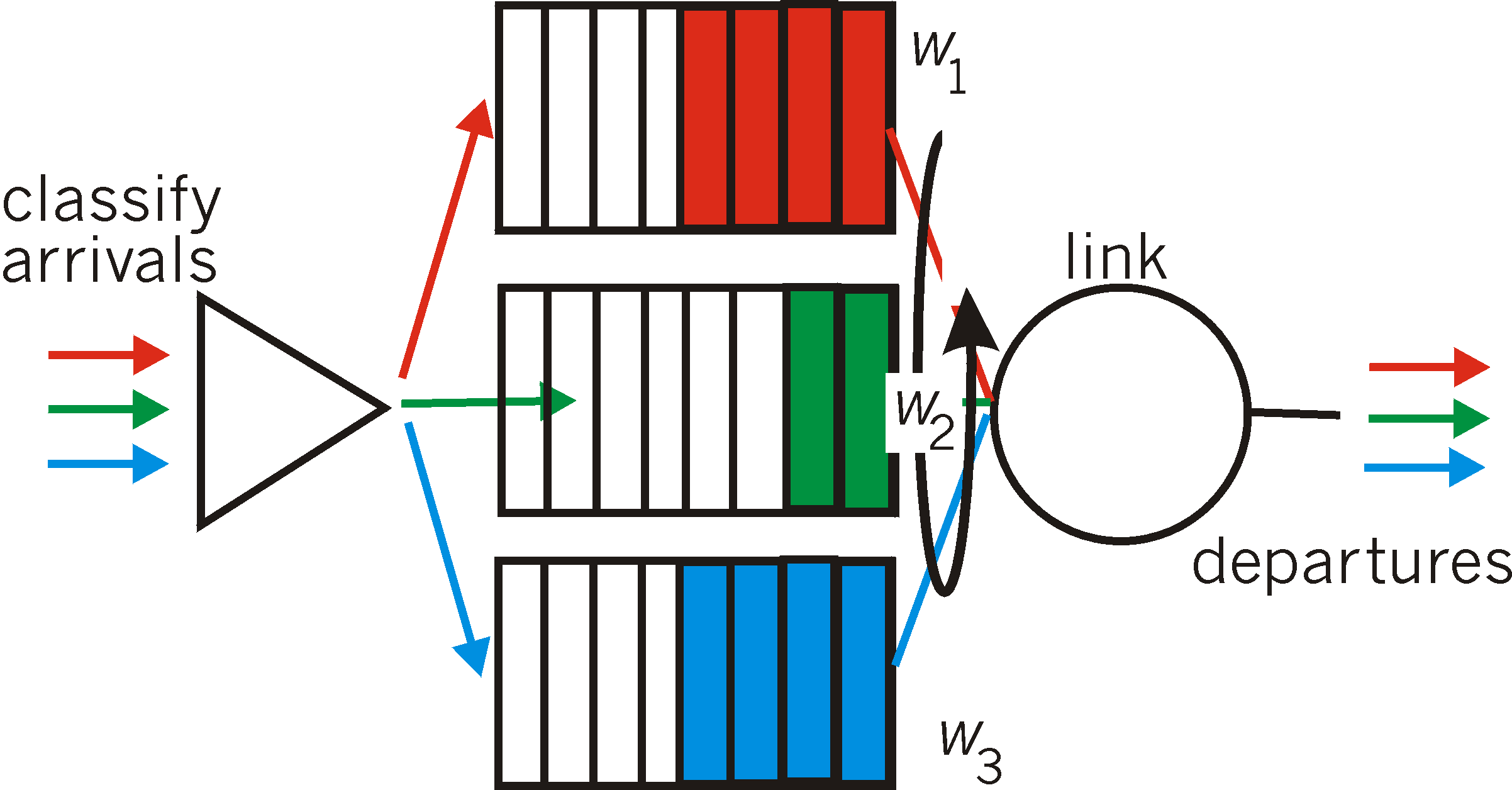
Under priority queuing, packets arriving to the output link are classified into one of two or more priority classes at the output queue, as shown in Figure 6.6-3. As discussed in the previous section, a packet's priority class may depend on an explicit marking that it carries in its packet header (e.g., the value of the Type of Service (ToS) bits in an IPv4 packet), its source or destination IP address, its destination port number, or other criteria. Each priority class typically has its own waiting area (queue). When choosing a packet to transmit, the priority queuing discipline will transmit a packet from the highest priority class that has a non-empty queue (i.e., has packets waiting for transmission). The choice among packets in the same priority class is typically done in a FIFO manner.
Figure 6.6-4 illustrates the operation of a priority queue with two priority classes. Packets 1,3 and 4 belong the the high priority class and packets 2 and 5 belong to the low priority class. Packet 1 arrives and, finding the link idle, begins transmission. During the transmission of packet 1, packets 2 and 3 arrive and are queued in the low and high priority queues, respectively. After the transmission of packet 1, packet 3 (a high priority packet) is selected for transmission over packet 2 (which, even though it arrived earlier, is a low priority packet). At the end of the transmission of packet 3, packet 2 then begins transmission. Packet 4 (a high priority packet) arrives during the transmission of packet 3 (a low priority packet). Under a so-called non-preemptive priority queuing discipline, the transmission of a packet is not interrupted once it has begun. In this case, packet 4 queues for transmission and begins being transmitted after the transmission of packet 2 is completed.
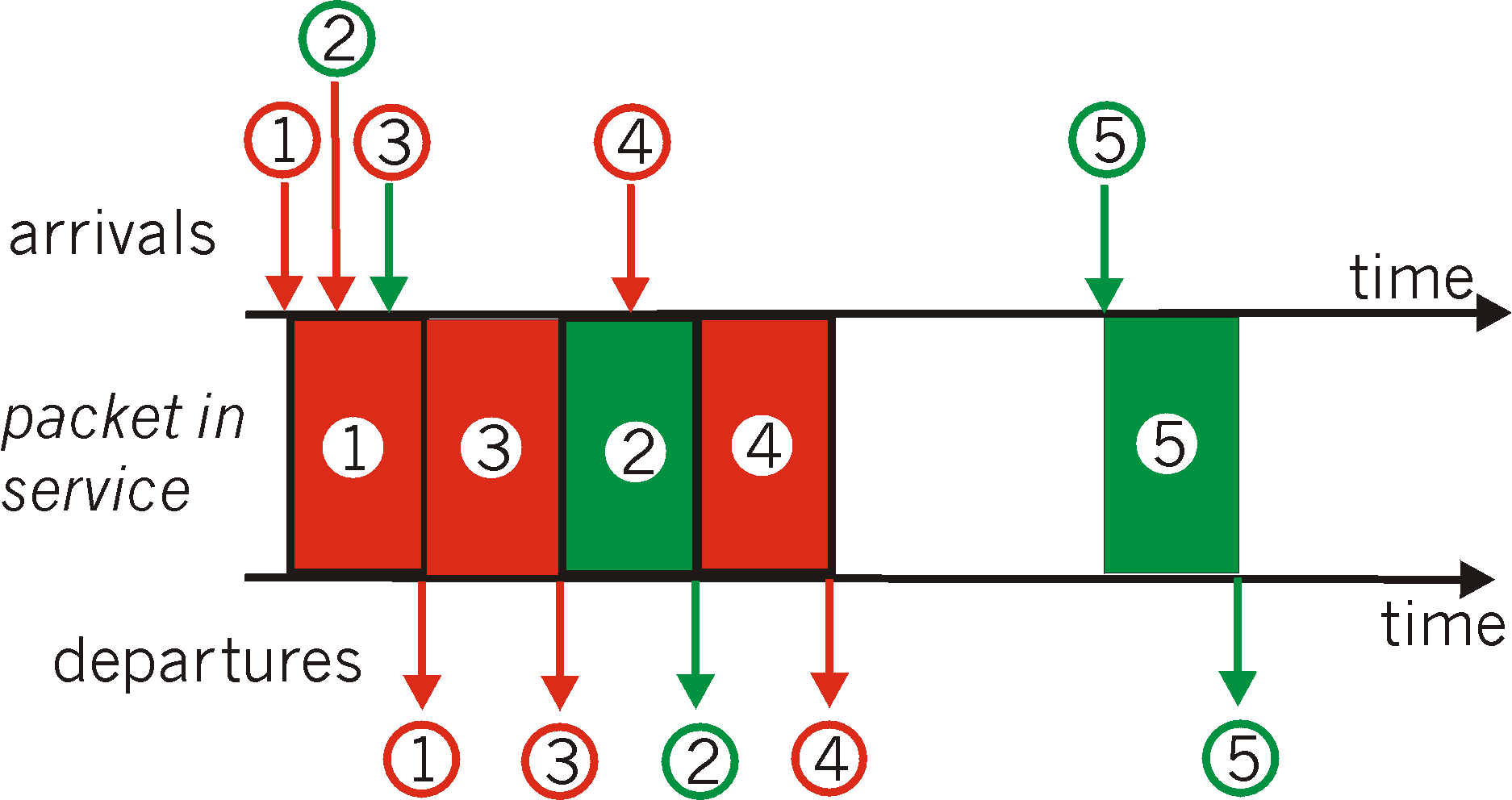
Figure 6.6-5 illustrates the operating of a two-class round robin queue. In this example, packets 1, 2 and 4 belong to class one, and packets 3 and 5 belong to the second class. Packet 1 begins transmission immediately upon arrival at the output queue. Packets 2 and 3 arrive during the transmission of packet 1 and thus queue for transmission. After the transmission of packet 1, the link scheduler looks for a class-two packet and thus transmits packet 3. After the transmission of packet 3, the scheduler looks for a class-one packet and thus transmits packet 2. After the transmission of packet 2, packet 4 is the only queued packet; it is thus transmitted immediately after packet 2.
A generalized abstraction of round robin queuing that has found considerable use in QoS architectures is the so-called Weighted Fair Queuing (WFQ) discipline [Demers 90, Parekh 93]. WFQ is illustrated in Figure 6.6-6. Arriving packets are again classified and queued in the appropriate per-class waiting area. As in round robin scheduling, a WFQ scheduler will again serve classes in a circular manner - first serving class 1, then serving class 2, then serving class 3, and then (assuming there are three classes) repeating the service pattern. WFQ is also a work-conserving queuing discipline and thus will immediately move on to the next class in the service sequence upon finding an empty class queue.
WFQ differs from round robin in that each class may receive a differential
amount
of service in any interval of time. Specifically, let each class, i,
is assigned a weight, wi. Under WFQ, during any interval
of time during which there are class i packets to send, class
i will then be guaranteed to receive a fraction of service equal to
wi/(Swj),
where
the sum in the denominator is taken over all classes that also have packets
queued for transmission. In the worst case, even if all classes have
queued packets, class i will still be guaranteed to receive a fraction
wi/(Swj),
of the bandwidth. Thus, for a link with transmission rate R,
class i
will always achieve a throughput of at least R.wi/(Swj).
Our
description of WFQ has been an idealized one, as we have not considered
the fact that packets are discrete units of data and a packet's transmission
will not be interrupted to begin transmission another packet; [Demers
90], [Parekh 93] discuss this packetization
issue. As we will see in the following sections, WFQ plays
a central role in QoS architectures. It is also widely available
in today's router products [Cisco 1999].
(Intranets that use WFQ-capable routers can therefore provide QoS to their
internal flows.)
In the section 6.5 we also identified policing, the regulation
of the rate at which a flow is allowed to inject packets into the network,
as one of the cornerstones of any QoS architecture. But what aspects of
a flow's packet rate should be policed? We can identify three important
policing criteria, each differing from the other according to the time
scale over which the packet flow is policed:
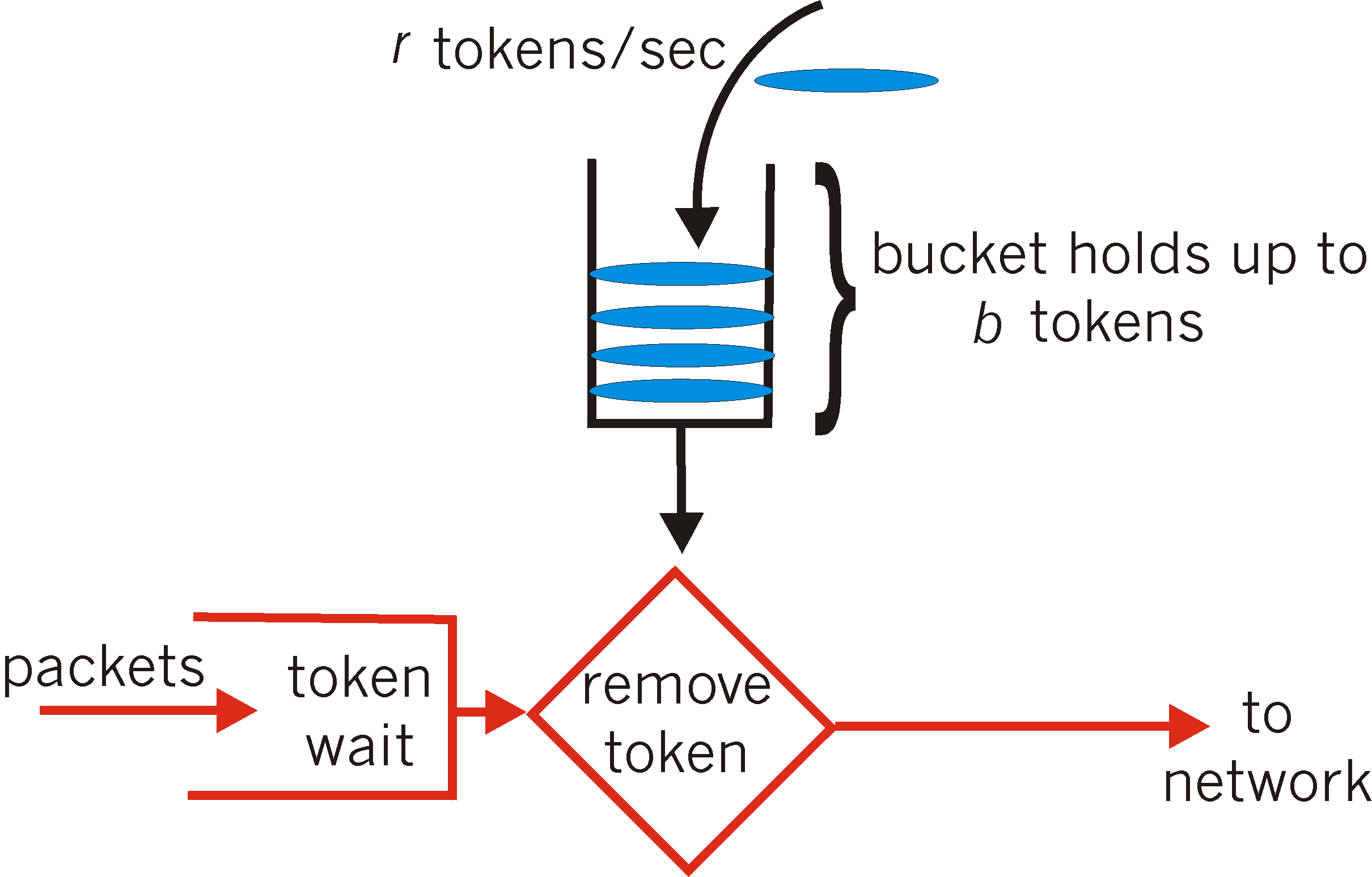
The leaky bucket (also call a token bucket) mechanism is an abstraction that can be used to characterize these policing limits. As shown in Figure 6.6-7, a leaky bucket consists of a bucket that can hold up to b tokens. Tokens are added to this bucket as follows. New tokens, which may potentially be added to the bucket, are always being generated at a rate of r tokens per second. (We assume here for simplicity that the unit of time is a second.) If the bucket is filled with less that b tokens when a token is generated, the newly generated token is added to the bucket; otherwise the newly generated token is ignored, and the token bucket remains full with b tokens.
Let us now consider how is the leaky bucket can be used to police a packet flow. Suppose before a packet is transmitted into the network, it must first remove a token from the token bucket. If the token bucket is empty, the packet must wait for a token. (An alternative is for the packet to be dropped, although we will not consider that option here.) Let us now consider how this behavior polices a traffic flow. Because there can be at most b tokens in the bucket, the maximum burst size for a leaky-bucket-policed flow is b packets. Furthermore, because the token generation rate is r, the maximum number of packets that can enter the network of any interval of time of length t is rt+b. Thus, the token generation rate, r, serves to limit the long term average rate at which packet can enter the network. It is also possible to use leaky buckets (specifically, two leaky buckets in series) to police a flow's peak rate in addition to the long-term average rate; see the homework problems at the end of this Chapter.
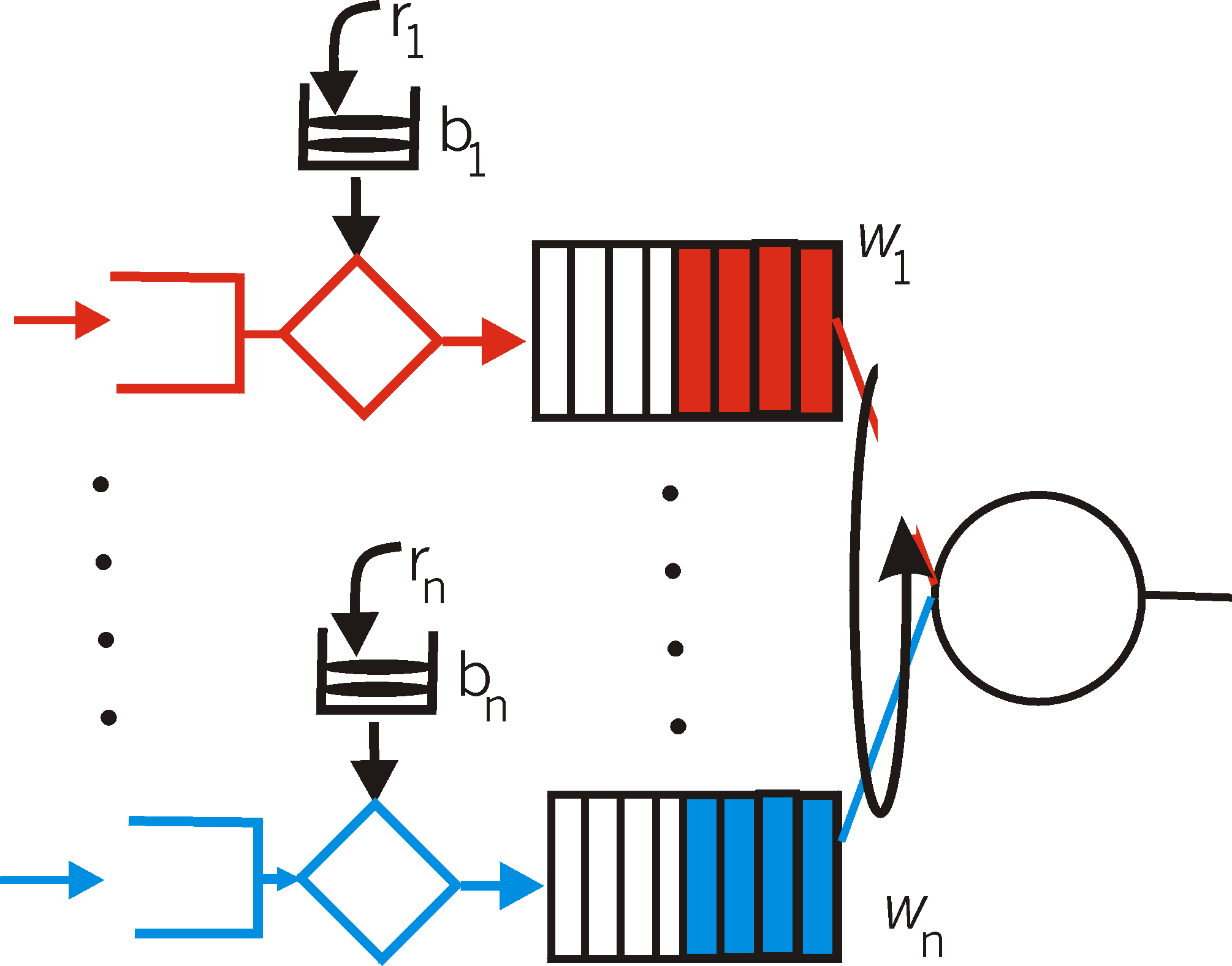
Figure 6.6-8: n multiplexed leaky bucket flows with WFQ
scheduling
Recall from our discussion of WFQ that each flow is guaranteed to receive a share of the link bandwidth equal to at least R.wi/(Swj), where R is the transmission rate of the link in packets/sec. What then is the maximum delay that a packet will experience while waiting for service in the WFQ (i.e., after passing through the leaky bucket)? Let us focus on flow 1. Suppose that flow 1's token bucket is initially full. A burst of b1 packets then arrives to the leaky bucket policer for flow 1. These packets remove all of the tokens (without wait) from the leaky bucket and then join the WFQ waiting area for flow 1. Since these b1 packets are served at a rate of at least R.wi/(Swj) packet/sec., the last of these packets will then have a maximum delay, dmax, until its transmission is completed, where
The justification of this formula is that if there are b1
packets in the queue and packets are being serviced (removed) from the
queue at a rate of at least C.wi/(Swj)
packets
per second, then the amount of time until the last bit of the last packet
is transmitted can not be more than b1/ (C.wi/(Swj)).
A
homework problem asks you prove that as long as r1 <
C.wi/(Swj),
then
dmax is indeed the maximum delay that any packet in flow
1 will ever experience in the WFQ queue.
Copyright James F. Kurose and Keith W. Ross 1996-2000