
THIS MATERIAL IS EXTRACTED FROM:
Deep Learning – Teoria e Prática, Cristina Nader Vasconcelos and
Esteban Clua. In Jornada de Atualização em Informática 2017, Sociedade
Brasileira da Computação, ISBN 978-85-7669-374-1, pp 217-260, 2017.
bibtex:
@incollection{NADCLUA2017,
author = “Cristina Nader Vasconcelos and Esteban Clua”,
title = “Deep Learning – Teoria e Prática”,
booktitle = “Jornada de Atualização em Informática 2017”,
year = “2017”,
pages = “217-260”,
editor = “Flávia C. Delicato and Paulo F. Pires”,
organization = “Sociedade Brasileira da Computação”,
publisher “Sociedade Brasileira da Computação”,
key = “Neural Networks, Convolutional Neural Networks, Recurrent
Neural Networks, LSTM, AlexNet, LeNet, ResNet, Inception”
ISBN = ” 978-85-7669-374-1″,
}
Nessa página trazemos informações sobre Deep Learning e suas ferramentas.
O material deste site foi apresentado na 36 Jornada de Atualização em Informática (JAI), evento realizado em conjunto com o Congresso da SBC 2017 na cidade de São Paulo em 06 de julho de 2017.
O livro do 36 JAI pode ser obtido aqui.
Slides do JAI (CSBC) – Deep Learning – Teoria e Prática
Parte 1 РIntrodṳ̣o.
Parte 2 – Fundamentos.
Parte 3 – GPUs
Parte 4 – Redes Recorrentes e LSTM.
Parte 5 РRedes Neurais de Convolṳ̣o.
Parte 6 – Prática de GPU – DIGITS
Material elaborado por Bruno Augusto Dorta Marques , Cristina Nader Vasconcelos e Esteban Clua
Ferramentas
Avanços em ferramentas e bibliotecas para o desenvolvimento de redes neurais profundas permitem a engenheiros, cientistas e entusiastas explorar soluções para diferentes aplicações na área de Aprendizado de Máquina, tais como classificação de imagens e vídeo, processamento natural de linguagem e reconhecimento de áudio. Essas ferramentas permitem que usuários treinem, desenvolvam e testem redes neurais profundas utilizando todo poder computacional proporcionado pelas GPUs. As bibliotecas de redes neurais profundas mais recentes apresentam uma forma de interação em alto nível onde o usuário deve se preocupar apenas com a modelagem da rede, sendo transparente ao usuário as etapas de mais baixo nível de programação e otimização computacional. Entre as bibliotecas mais populares encontram-se: Caffe, CNTK, Tensor Flow, Torch e Theano.
Caffe
Caffe é uma biblioteca de aprendizado profundo desenvolvido em conjunto pelo grupo de pesquisa Berkeley AI Research (BAIR) e por contribuidores da comunidade de Software Livre. O Caffe foi desenvolvido para que modelos e otimizações possam ser definidos facilmente através de arquivos de configurações e uma linguagem de definição chamada Protobuf Model Format.
Um arquivo Protobuf permite a especificação dos parâmetros utilizados pela rede neural, bem como as camadas que compõem a rede neural profunda. Os arquivos de definição de redes são salvos como texto no formato Protobuf, já os pesos aprendidos pela rede são serializados e salvos em um arquivo Protobuf binário. Esse formato permite que redes possam ser facilmente compartilhadas entre a comunidade, sendo possível treinar, testar e repetir os experimentos das redes neurais de outros usuários.
Além da configuração da rede, o Caffe disponibiliza uma estrutura de dados para armazenar e realizar a comunicação entre as camadas da rede chamada Blob. Um Blob é capaz de alocar e gerenciar a memória entre a CPU e GPU de forma automática e sem a intervenção do usuário. Isso permite que usuários se concentrem na modelagem da rede e não em sua implementação computacional.
Um fluxo de trabalho típico utilizando o Caffe segue os passos a seguir: O primeiro passo necessário é converter os dados de entrada, incluindo os conjuntos de treinamento, validação e treinamento, para um formato aceito pelo Caffe. Entre os formatos aceitos estão : LMDB, levelDB e hdf5. Sendo os dois primeiros formatos os mais aceitos e utilizados para problemas de classificação de imagens e vídeos. LMDB permite a leitura concorrente de dados e possui alta compatibilidade com diferentes sistemas operacionais. Já o levelDB costuma gerar bases de dados com tamanhos mais compactos. O formato hdf5 é utilizada em problemas que não utilizam um único rótulo de classificação, mas um vetor de dados como rótulo.
A definição da rede consiste em criar um arquivo de texto no formato Protobuf contendo as informações relevantes a arquitetura da rede. A definição deve obrigatoriamente conter uma camada especificando o formato dos dados de entrada, incluindo, nome das camadas de entrada e rótulos, caminho para o banco de dados contendo as imagens, tamanho do batch de processamento e transformações de dados. As transformações de dados incluem operações típicas de imagens, tais como: alterações de escala, espelhamento e recortes. Não é possível utilizar transformações de dados em base de dados no formato hdf5.
Além da entrada de dados, o usuário deve inserir as camadas intermediarias e finais da rede. Essas camadas podem ser de diversos tipos, entre os mais utilizados estão: convolução (do inglês em convolution), pooling, recorte (do inglês crop), recorrente (do inglês recurrent), dropout, Relu, produto Interno (do inglês, inner product), Softmax, perda (do inglês loss). Sendo a camada do tipo Produto interno uma camada totalmente conectada, comumente utilizada ao final da rede em conjunto com uma camada de Perda. A camada de Perda é utilizada na fase de treinamento da rede, onde a saída da rede é comparada a uma função objetivo, isso permite a rede ajustar os pesos para que passe a acertar e minimizar o erro em sua saída. O passo final antes do treinamento é definir os parâmetros utilizados pelo solver. Isso pode ser feito em um arquivo prototxt. Os parâmetros típicos de treinamento incluem:
- base_lr, é a taxa de aprendizagem base utilizada durante todo o processo de treinamento da rede. Essa taxa base pode ser alterada em camadas específicas na definição da rede através de um fator multiplicativo chamado lr\textunderscore mult.
- max_iter, é o número máximo de iterações que o solver deve executar
- snapshot, determina o intervalo, em iterações, utilizado para a criação de um ponto de checagem (Snapshot). O arquivo de ponto de checagem é criado em uma frequência definida por um número fixo de iterações. O Ponto de checagem permite dar continuidade a um treinamento interrompido, sem a necessidade de iniciar um novo processo de treinamento a partir do início.
- snapshot\textunderscore prefix: prefixo utilizado no nome do arquivo de ponto de checagem.
É necessário especificar o solver utilizado e seus parâmetros. Os solvers disponíveis no Caffe são: Stochastic Gradient Descent (SGD) , AdaDelta (AdaDelta) , Adaptive Gradient (AdaGrad) , Adam (Adam) , Nesterov’s Accelerated Gradient (Nesterov) e RMSprop (RMSProp) . A partir dos arquivos de configuração e definição da rede, é possível treinar uma rede e obter um arquivo contendo os pesos aprendidos em todas as camadas durante o processo de treinamento. Os pesos são salvos em um arquivo do tipo Protobuf binário e podem ser utilizados para realizar testes e inferências na rede neural.
Nvidia Digits
Nvidia DIGITS é um sistema de treinamento em GPU de redes neurais profundas desenvolvido pela Nvidia e pela comunidade de Software Livre. O DIGITS permite que usuários desenvolvam, treinem e visualizem redes neurais profundas através de uma interface intuitiva e amigável diretamente em um browser de internet. Atualmente, o DIGITS pode ser utilizado com três frameworks de Rede neurais profundas: Caffe, Torch e Tensor Flow.
Uma das facilidades oferecidas pelo DIGITS é a criação e gerenciamento de banco de dados no formato LMDB ou HDF5. É possível criar todo o banco de dados utilizando apenas a interface web, incluindo as imagens de treinamento, validação e testes.
O usuário pode descrever o caminho das pastas contendo as imagens e seus respectivos rótulos de duas maneiras diferentes. A primeira é organizar os arquivos em pastas onde o nome da pasta corresponde ao rótulo de classificação.
A segunda maneira é fornecer ao DIGITS um arquivo de texto contendo o caminho de cada imagem seguido de um valor numérico que identifique o seu rótulo. O valor numérico deve varia de 0 a N-1, onde N é o número de classes do problema a ser tratado. Ainda através dessa interface é possível especificar separadamente o conjunto de treinamento, validação e testes ou ainda fornecer um único conjunto de dados e especificar qual a porção de dados será utilizada em cada etapa.
Caso o usuário siga por esse último modo, ele deve especificar a porção (em porcentagem) de imagens utilizadas para cada etapa, assim o DIGITS irá sortear aleatoriamente as imagens e criar o banco de dados no formato escolhido.
O DIGITS disponibiliza uma lista contendo todos os banco de dados criados pelo usuário, onde é possível visualizar facilmente a quantidade e quais imagens pertencem a cada classe. Uma grande vantagem do DIGITS é a habilidade de facilmente treinar novas redes e de visualizar redes já treinadas anteriormente. É possível comparar a acurácia e os processos de treinamento entre as redes já treinadas.
O Treinamento de uma nova rede consiste em selecionar através da interface de treinamento uma das bases de dados criadas anteriormente e especificar os parâmetros de treinamento. Esses parâmetros são os mesmo descritos na Seção anterior. Todos os parâmetros estão visíveis ao usuário, bastando a escolha dos valores nas caixas de texto da interface web. O usuário deve escolher também uma arquitetura de rede profunda.
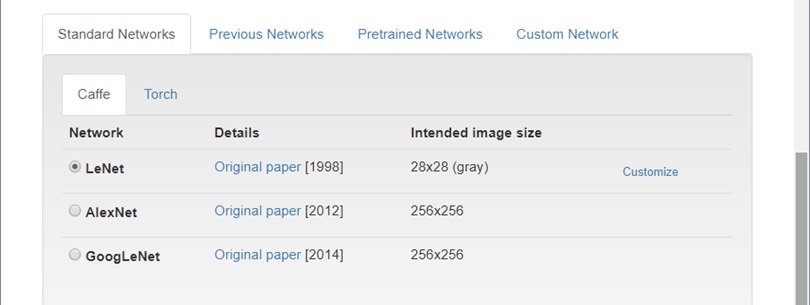
O DIGITS permite ao usuário selecionar uma das três arquiteturas disponíveis: LeNet, AlexNet, GoogLeNet. O usuário também pode especificar uma rede neural customizada, bastando inserir a definição da rede no formato Protobuf em uma caixa de texto disponível na interface do DIGITS. As definições da rede devem seguir as regras da biblioteca Caffe, Torch ou Tensor Flow.
Diferentemente do método tradicional de configuração (Sem a utilização do DIGITS), não é necessário especificar a camada de entrada de dados, já que o DIGITS é capaz de inferir essas configurações a partir da base de dados criada pelo usuário. Essa facilidade fornecida pelo DIGITS permite a rápida criação e treinamento de redes neurais capazes de funcionarem em banco de dados de diferentes características (tais como quantidade de canais de cores, tamanho e formato das imagens) sem a intervenção do usuário no arquivo de definição da rede.
O usuário é livre para escolher qual GPU deverá ser utilizada durante o treinamento, podendo inclusive selecionar múltiplas GPUs a fim de diminuir o tempo necessário para o processamento. Durante o processo de treinamento, é possível visualizar informações em tempo real, tais como as saídas da rede (acurácia de treinamento, acurácia de validação, erro), quantidade de épocas, estimativa de tempo necessário para o fim do treinamento e uso de recursos de hardware, incluindo uso de CPU, GPU e Memória.
Ao término do processo de treinamento, o usuário é capaz de testar a rede utilizando dois métodos implementados na interface web do DIGITS. O teste pode ser feito em uma única imagem, onde é possível gerar dados estatísticos e imagens contendo mapas de calor representando os pesos e ativações das camadas da rede neural profunda.
Além disso é possível verificar a classificação final e o rótulo de classificação. Outro modo de teste consiste em treinar múltiplas imagens de uma só vez. Nesse modo o usuário deve especificar um arquivo de texto contendo o caminho das imagens. Caso seja fornecido um rótulo associado as imagens, o sistema gera informações de acurácia do teste, incluindo uma tabela de confusão dos resultados. A interface permite que o teste seja conduzido com base nos pesos aprendidos em qualquer uma das épocas de treinamento.
O DIGITS oferece uma opção para realizar o download das definições de rede, solver e pesos da rede treinamento, facilitando assim a transferência dos resultados para outras máquinas ou implementação do sistema final. O Nvidia DIGITS é uma ferramenta muito valiosa para usuários e pesquisadores de redes neurais profundas pois permite o rápido gerenciamento de redes neurais profundas e facilita todo o processo, desde a criação da base de dados, passando pelo treinamento, até o teste de redes neurais profundas. Todo o processo pode ser realizado sem a necessidade da criação manual de arquivos de texto contendo configurações ou scripts.
Construindo um Classificador de Imagens utilizando o DIGITS
Nessa seção iremos construir um classificador de dígitos utilizando uma arquitetura de rede já conhecida chamada LeNet-5. A base de dados utilizadas será a MNIST. Essa é uma base de dados contendo 60.000 imagens anotadas de um único dígito escritos a mão. Cada imagem é composta por um único dígito, centralizado e sem nenhuma imagem de fundo. A imagens dessa base da dados possuem tamanho de 28 x 28 pixels. A base de dados está publicamente disponivel no site de seu criador, Yann LeCun.
Com o digits instalado, voce pode facilmente fazer download do dataset utilizando o seguinte comando:
python -m digits.download_data mnist ~/mnist
isso irá criar o dataset na pasta mnist dentro da pasta local de seu usuário.
Criando a base de dados
Para criarmos a base de dado no dígits é necessário acessar o seu navegador de internet no endereço http://localhost/ ou http://localhost:5000/. Isso irá exibir a tela inicial do DIGITS.
A partir dessa tela, selecione a opção
Datasets, New Dataset > Images > Classification
será necessário fornecer um nome de login para seu usuário.
Após efetuado o Login, voce irá visualizar a tela de criação de base de dados. Nessa tela selecione as configurações referentes as imagens:
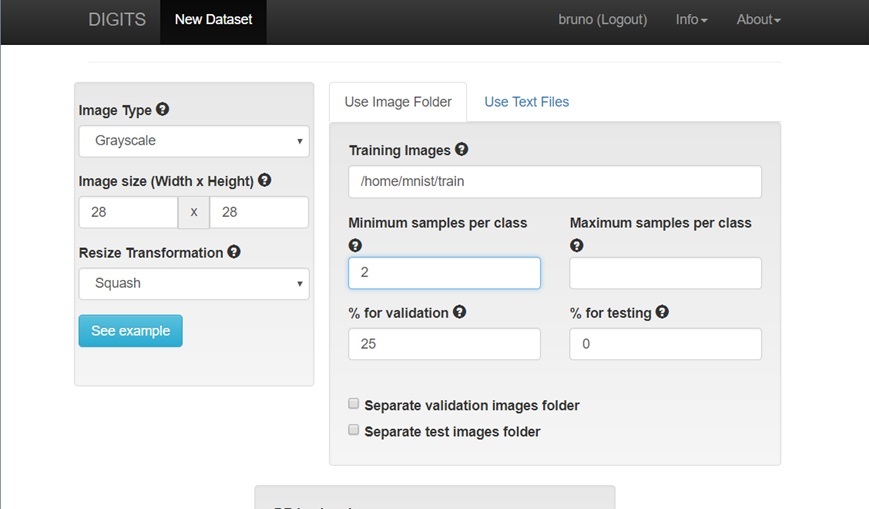
As seguintes alterações devem ser efetuadas:
- Mude as opçoes de tipo de imagem para imagens em escala de cinza (Grayscale)
- Mude o tamanho da imagem para 28 x 28 pixels
- Dê um nome para a sua base de dados (ex. mnistDB)
Altere tambem o caminho para a pasta contendo o dataset MNIST (em nosso exemplo será ~/mnist, onde ~/ é o caminho completo para o seu usuário no sistema).
Clique em Create para criar a sua Base de Dados.
Você poderá conferir o status da criação na tela a seguir.
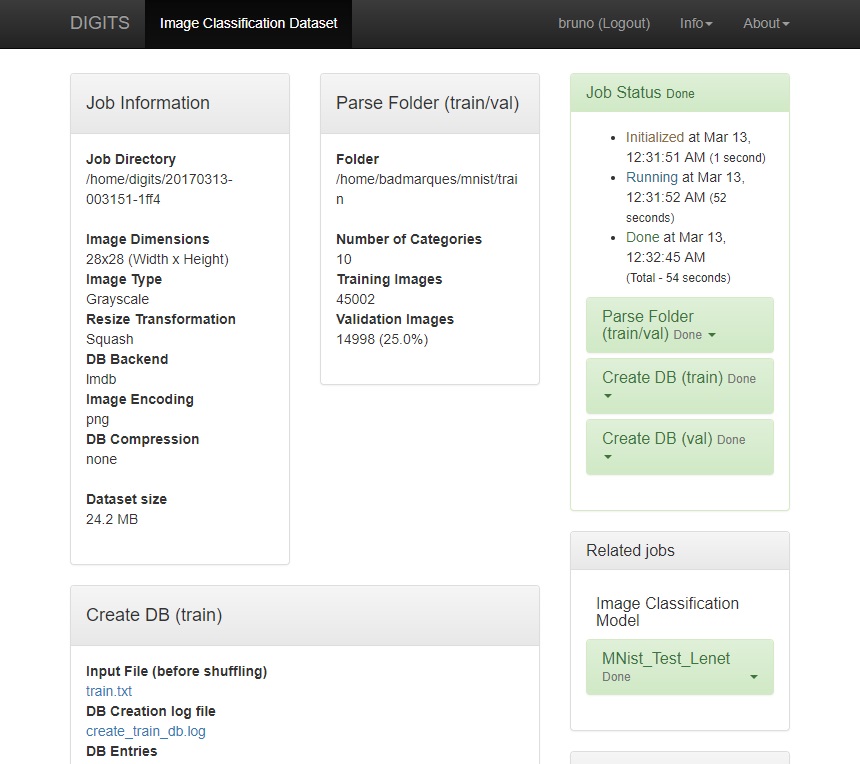
Assim que as tarefas Create DB train e val estiverem completas, voce poderá prosseguir para a próxima seção (Treinando a rede).
Treinando a rede neural
A partir da tela inicial do DIGITS, selecione a opção
Models > New Model > Images > Classification
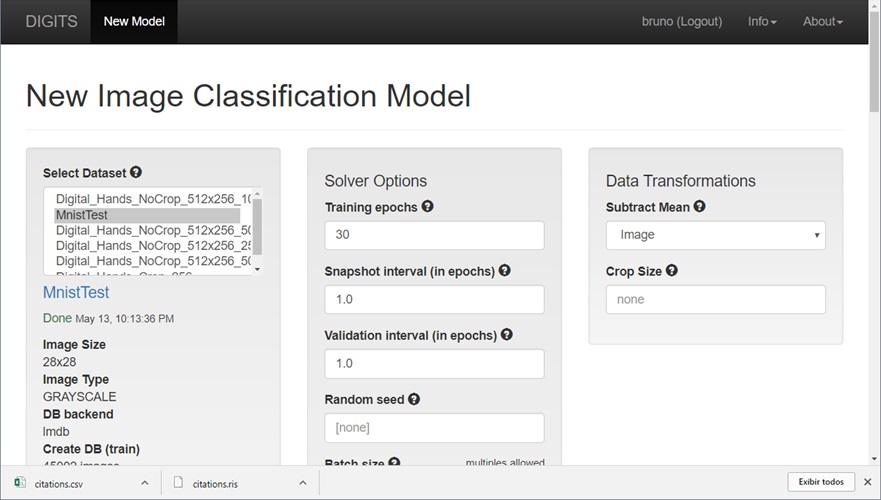
Para treinar a rede, devemos primeiro escolher a base de dados criada na seção anterior no Menu Select Dataset (ex: mnistDB). Para esse exemplo, iremos utilizar os valores padrões do digits:
- Épocas de treinamento (Training Epoch): 30
- Intervalo de snapshot: 1
- Intervalo de validação: 1
- Solver Type: SGD
- Taxa de aprendizagem (Learning Rate): 0.01
Vamos utilizar uma das redes padrões que é a LeNet. Essa rede foi construÃda justamente para tratar problemas de reconhecimento de dígitos, e espera uma base de dados com imagens de tamanho 28 x 28 em escala de cinza, idêntica as imagens do dataset que estamos utilizando.
Enquanto efetuamos o treinamento, podemos conferir em tempo real a estimativa de tempo para conclusão da tarefa e o gráfico de acurácia e erro como mostra a imagem abaixo:
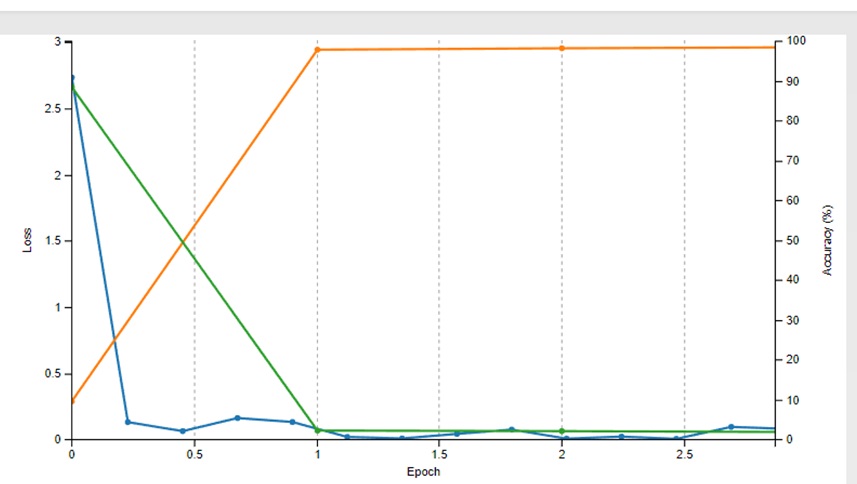
O acerto (accuracy em laranja) e o erro (loss) são atualizados em tempo real no gráfico de status do treinamento. É possÃvel interromper trabalho antes de seu término, essa opção é utilizada quando a rede atinja o valor esperado antes do término da tarefa.
Testando a rede
Para testar o modelo treinado, podemos ir até até a seção Trainer Models de sua rede e selecionar a época de teste.
A melhor época de teste consiste naquela que possui a maior taxa de acerto (accuracy) e o menor erro na validação (loss val).
No DIGITS, temos duas opções, podemos testar uma única imagem, ou realizar uma bateria de testes, com múltiplas imagens.
Vamos testar a rede com uma única imagem.
Selecione uma imagem de dígito contida na pasta train do dataset Mnist, Esse procedimento pode ser realizado a partir do botão Browse no campo Upload Image do DIGITS.
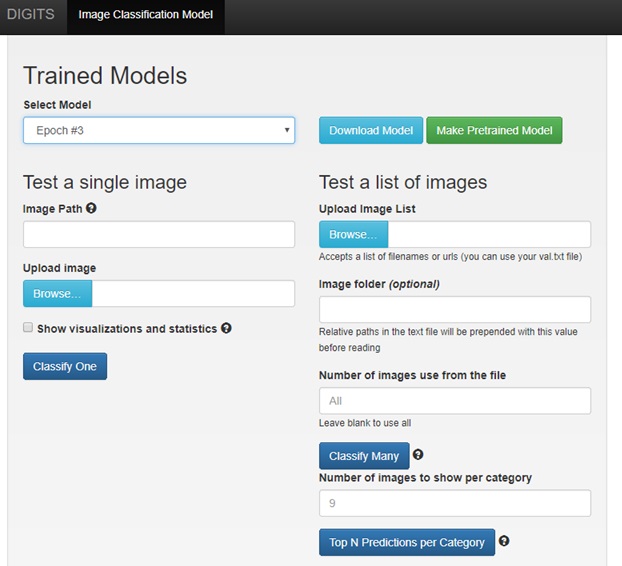
ou insira o caminho de alguma imagem de um único dígito retirado da internet, o caminho deve ser inserido no campo Image Path da seção Test a single image.
As imagens devem seguir o padrão do mnist, ou seja, imagens em escala de cinza, contendo apenas um único dígito centralizado.
Clique em Classify One.
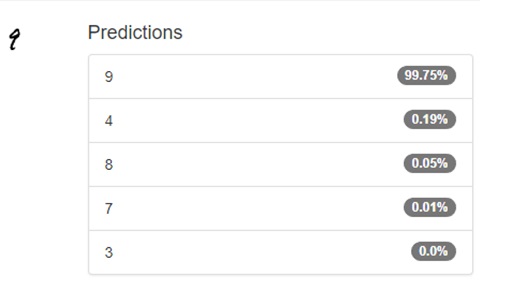
A Classificação da sua imagem pode ser conferida na tela a seguir. Como é possÃvel observar, não é exibido uma única classe, mas sim as 5 classes com maior probabilidade. Caso queira ver estatÃsticas da sua rede, bem como as camadas de ativação de cada uma das camadas da rede, selecione a opção show visualizations and statistics na interface de teste da rede.
Construindo uma rede para segmentação de Imagens
A segmentação de imagens é uma técnica muito utilizada para resolver problemas nas areas de processamento de imagens, visão computacional e aplicações inteligentes. A segmentação de imagens consiste na classificação de parte das imagens em uma classe pré determinada, logo podemos tratar a segmentação de imagens como uma generalização do problema de classificação de imagens.
Diferentemente da cliassificação de imagens, onde uma única imagem recebe um único rótulo (classe). Na segementação de imagens dividmos uma imagem em blocos. Idealmente, a divisão é feita em nÃveis de pixels, onde cada pixel é um bloco da segmentação.
Cada bloco da segmentação recebe uma distribuição de probabilidade, que o classifica em uma das classes do problema.
Construindo a base de dados
Nesse exemplo, iremos utilizar a base de dados SYNTHIA. Essa base é composta por imagens geradas artificialmente, contendo uma ambiente urbano. As imagens são anotadas em blocos onde cada pixel pertence a uma das classes. As classes presentes nessa base incluem construções, pedestres, carros, sinais de trânsito.

A partir da tela inicial do DIGITS, selecione a opção
Datasets > New Dataset > Images > Segmentation
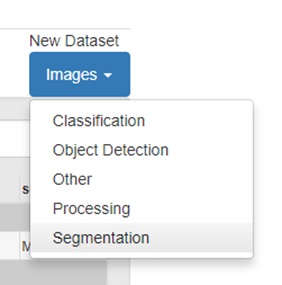
Caso não esteja logado no sistema, será necessário fornecer um nome de login para seu usuário. A tela para criação de uma base de dados para segmentação possui opções diferentes da aplicação anterior (classificação de imagens).
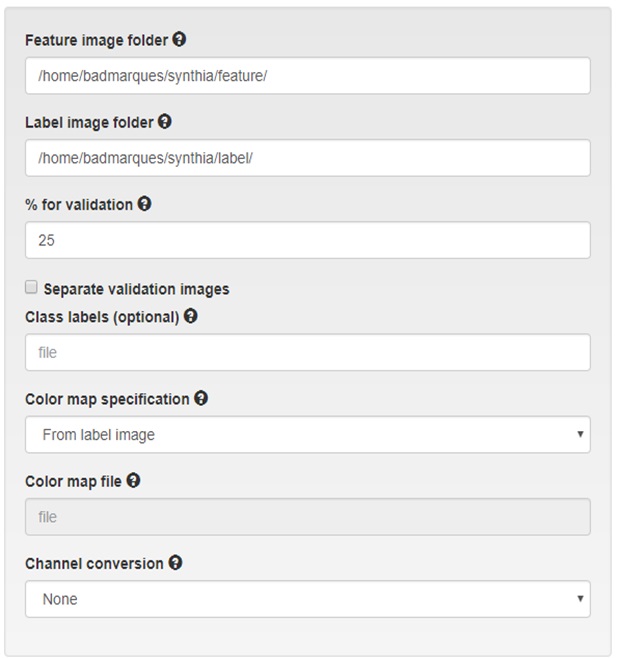
Nela temos que inserir dois caminhos para as imagens:
- Feature image folder: é o caminho das imagens inalteradas do dataset, as imagens podem ser coloridas ou em escala de cinza
- Label image folder: é o caminho das imagens que contêm os rótulos, ou seja, as classes a que cada pixel pertênce. Essas imagens podem ser de um único canal (em escala de cinza) ou múltiplos canais (onde cada cor corresponde a uma classe diferente)
Caso deseje inserir o nome das classes de seu problema, é necessário inserir um arquivo de texto, onde cada linha contém o nome da classe correspondente.
Por exemplo, o arquivo:
Contruções Postes Ruas
Indica que a classe 0 será nomeada Construções. A classe 1 será nomeada Postes. A classe 2 será nomeada Ruas.
Para imagens de rótulo coloridas, caso específique um arquivo de rótulos, é necessário específicar a cor que cada classe representa. Essa opção é chamada de Color map file, onde cada linha do arquivo de color map segue o seguinte padrão:
R G B Número da classe
Por Exemplo, o arquivo abaixo :
255 0 0 1 0 0 255 2
Indica que a cor vermelha (255, 0, 0) pertence a classe 1. A cor azul (0,0, 255) pertence a classe 3.
Treinando a rede
Para criar e efetuar o treinamento da rede:
A partir da tela inicial do DIGITS, selecione a opção
Datasets > New Model > Images > Segmentation
Na caixa Data Transformations, alteramos o campo subtract mean para none.
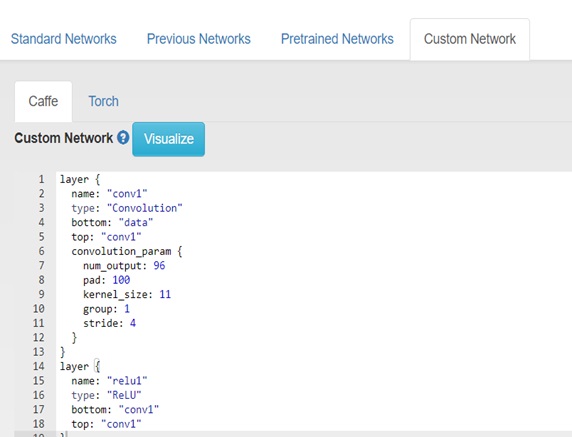
Vamos selecionar então a rede utilizada. Para isso adicione a definição de sua rede no campo custom network. Como estamos utilizando o framework Caffe, não esqueça de deixar essa opção marcada na interface do DIGITS.
Clique em Create para criar a sua Base de Dados.
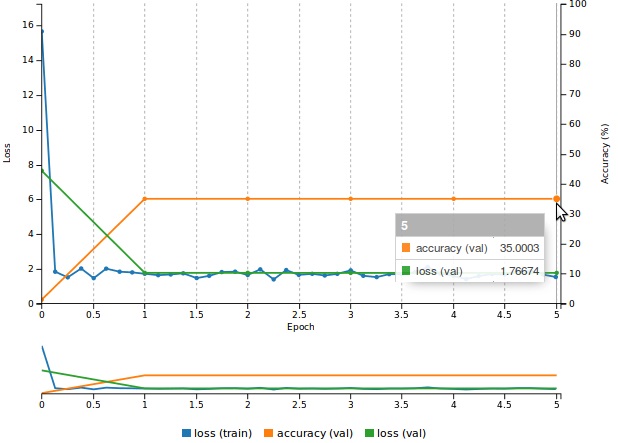
Ao visualizar o treinamento, notamos que a rede não possui uma grande taxa de acerto, identificamos uma taxa de aproximadamente 35% de acertos nos arquivos de validação. Ao observarmos o erro (loss), podemos perceber que a validação e o treino estão constantes, convergindo em uma reta. Isso indica que a rede esta num processo de underfitting.
Se terstamos a rede com uma imagem, vamos perceber que toda a imagem foi classificada como uma única classe. Nesse caso construção (building).

Esse problema ocorre pois a base de dados está desbalanceada, a classe de maior ocorrencia no dataset é a de contrução, logo caso a rede classifique todos os pixels como construção, ainda assim ela acerta 35% das ocorrencias.
Para resolver esse problema, podemos utilizar uma das seguintes soluções:
- Aumentar o tempo de treinamento: Em alguns casos, aumentar o tempo de treinamento pode ajudar a rede a achar uma solução melhor para o problema. Nesse caso específico a solução é pouco provavel, já que a rede encoutrou um mínimo local e encontra-se “presa” nesse mínimo. Podemos observar facilmente esse comportamento ao o gráfico do treinamento, a rede convergiu logo após uma única época de treinamento, permanecendo estável (e formando uma reta no gráfico).
- Aumentar a taxa de aprendizagem: Aumentar a taxa de aprendizagem faz com que a rede de passos maiores no momento da otimização, ajudando assim a sair de um mínimo local encontrado. Porém essa técnica aumenta a chance de divergência no treinamento.
- Aumentar o tamanho do modelo: O aumento do tamanho do modelo pode permitir a rede uma maior abstração dos dados. Modelos mais profundos costumam chegar a uma taxa de acerto superior, embora exijam uma quantidade maior de dados e um maior tempo de processamento.
Embora essas soluções possam ser aplicados, um método muito utilizado em aprendizado profundo é a transfêrencia de aprendizado ( do inglês Transfer Learning).
A transferência de aprendizado consistem em reutilizar o conhecimento aprendido pela rede treinada a partir de outra base de dados. Isso acontece porque features de mais baixo nível tal como detecção de bordas, linhas, formas e texturas podem servir para basicamente todos os problemas.
Para utilizarmos os pesos aprendidos de outro banco de dados, a rede deve possuir a mesma configuração de camadas e parâmetros, tais como tamamho dos filtros, passo, etc. Camadas que possuem o mesmo nome e mesma configuração terão seus pesos copiados. Camadas com nomes diferentes serão inicializadas com pesos aleatórios.
No exemplo anterior, inicializamos os pesos com valores aleatórios. Ao invês de utilizarmos os pesos aleatórios, podemos treinar a rede utilizando uma base de dados maior, tal como a ImageNet e inicializarmos a nossa rede com os pesos aprendidos desse exemplo. Como treinar uma rede com base de dados grandes requerem um grande poder computacional, a comunidade de aprendizado profundo costuma compartilhar as redes e os pesos já treinados.
Para facilitar o compartilhamento de redes, as versões mais recentes do DIGITS disponíbiliza um repositório chamado Model Store, onde é possivel importar redes já treinadas de outros usuários. Basta escolher uma das redes disponivies e clicar na opção importar.
Para treinar uma rede utilizando os pesos pré treinados, basta inserir o caminho do arquivo prototxt contendo os pesos da rede pré treinada no campo Pretrained model nas definições de rede

Com o novo treinamento, temos um resultado melhor que o anterior.

É possivel melhorar essa classificação, nesse caso a segmentação ainda se encontra grosseira, pois ao utilizarmos uma camada de deconvolução, estamos ampliando um bloco da imagem e perdendo definição na classificação.
Uma segmentação fina pode ser realizada se utilizarmos uma técnica que adiciona conexões de atalho as camadas intermediárias. Essa solução permito obtermos uma classificação a partir de features mais baixo nivel de nossa rede. A classificação final é uma somátoria das classificações onde há a conexão de atalho.
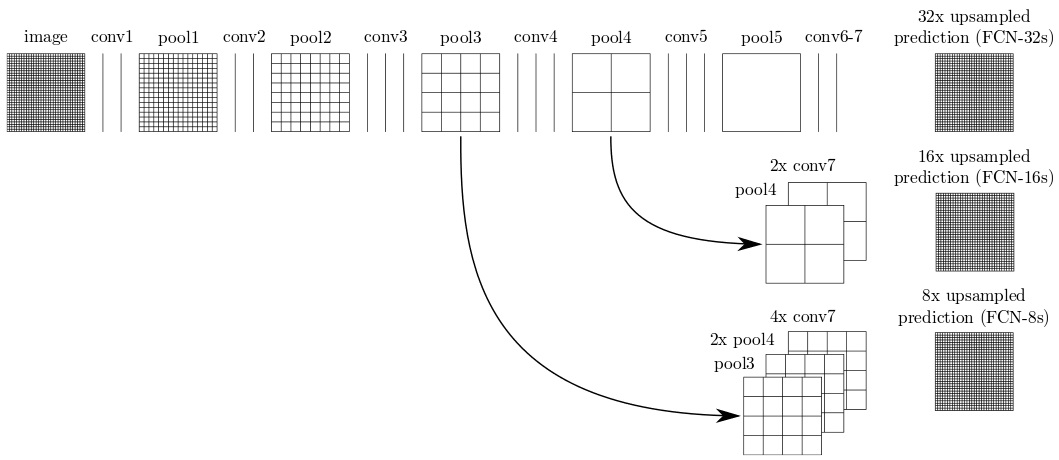
A rede FCN-8s disponível no Model store utiliza essa técnica.
Treinando uma rede FCN-8s utilizando o mesmo data-set, podemos obter um resultado melhor, alcançando 95% de acurácia.

Mais informações desse método podem ser encontradas nos seguinte artigo:
±Long, Jonathan, Evan Shelhamer, and Trevor Darrell. “Fully convolutional networks for semantic segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015: 3431-3440.
Essa seção foi baseada no artigo em inglês Image Segmentation Using DIGITS 5